
LambdaでExcelを操作してみた(openpyxl)
LambdaでExcelファイルを操作してみました。
S3バケットのエクセルを読み込み、編集して、新規ファイル保存し、S3バケットに格納します。
2024.07.24
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
私たち製造ビジネステクノロジー部では、製造業に関するエンドユーザや事業会社さんに対して、システムやサービスを事業会社さんと一緒に作成・運用しています。そんな製造業において、PLCなどのデータをエクセルにまとめるためにPythonでエクセルファイルを作成・更新をすることになりそうなので、LambdaでExcelの操作を試してみました。
- S3バケットのExcelをgetする
- LambdaでExcelを更新する
- S3バケットにExcelをputする
おすすめの方
- PythonでExcelを操作したい方
- LambdaでExcelを操作したい方
S3バケットやLambdaを作成する
sam init
sam init \
--runtime python3.11 \
--name lambda-excel-sample \
--app-template hello-world \
--no-tracing \
--no-application-insights \
--structured-logging \
--package-type Zip
requirements.txtにopenpyxlを記載する
requirements.txt
openpyxl
Lambdaコード
S3バケットからエクセルを取得し、更新し、別ファイル保存し、S3に格納しています。
今回は簡略化していますが、実際には次の対応をすると良いと思います。
- 別ファイル保存時のファイル名を重複しないようにする(UUIDを使うなど)
- Lambdaの/tmpに保存したファイル(別ファイル保存)は、最後に削除する
- 同じLambdaがたくさん実行された場合、容量が不足する可能性があるため
app.py
import os
import boto3
from datetime import datetime, timedelta, timezone
from openpyxl import load_workbook
# DynamoDBなどから取得したデータを想定しています
DATA = [
{"timestamp": 1690188000000, "temperature": 32.9, "humidity": 64},
{"timestamp": 1690191000000, "temperature": 30.7, "humidity": 58},
{"timestamp": 1690194000000, "temperature": 34.1, "humidity": 54},
{"timestamp": 1690197000000, "temperature": 36.5, "humidity": 59},
{"timestamp": 1690200000000, "temperature": 33.3, "humidity": 66},
{"timestamp": 1690203000000, "temperature": 29.8, "humidity": 49},
]
JST = timezone(timedelta(hours=+9), "JST")
s3 = boto3.client("s3")
BUCKET_NAME = os.getenv("BUCKET_NAME")
KEY_NAME = "sample.xlsx"
OUTPUT_FILE_NAME = "output.xlsx"
def lambda_handler(event, context):
local_file_path = download_file(BUCKET_NAME, KEY_NAME)
if local_file_path is None:
return {
"statusCode": 500,
}
output_file_path = os.path.join("/tmp", OUTPUT_FILE_NAME)
res = make_excel(local_file_path, output_file_path)
if res is None:
return {
"statusCode": 500,
}
upload_file(BUCKET_NAME, OUTPUT_FILE_NAME, output_file_path)
return {
"statusCode": 200,
}
def download_file(bucket_name: str, file_name: str) -> str | None:
local_file_path = os.path.join("/tmp", file_name)
s3.download_file(bucket_name, file_name, local_file_path)
if os.path.exists(local_file_path):
return local_file_path
return None
def make_excel(local_file_path: str, output_file_path: str) -> str | None:
wb = load_workbook(filename=local_file_path)
ws_test1 = wb["テスト1"]
for i, d in enumerate(DATA, start=2):
ws_test1[f"A{i}"] = datetime.fromtimestamp(
d["timestamp"] / 1000, tz=JST
).strftime("%Y-%m-%d %H:%M:%S")
ws_test1[f"B{i}"] = d["temperature"]
ws_test1[f"C{i}"] = d["humidity"]
wb.save(output_file_path)
if os.path.exists(output_file_path):
return output_file_path
return None
def upload_file(bucket_name: str, file_name: str, file_path: str) -> None:
s3.upload_file(file_path, bucket_name, file_name)
デプロイ
sam build --use-container
sam deploy \
--guided \
--region ap-northeast-1 \
--stack-name lambda-excel-sample-stack
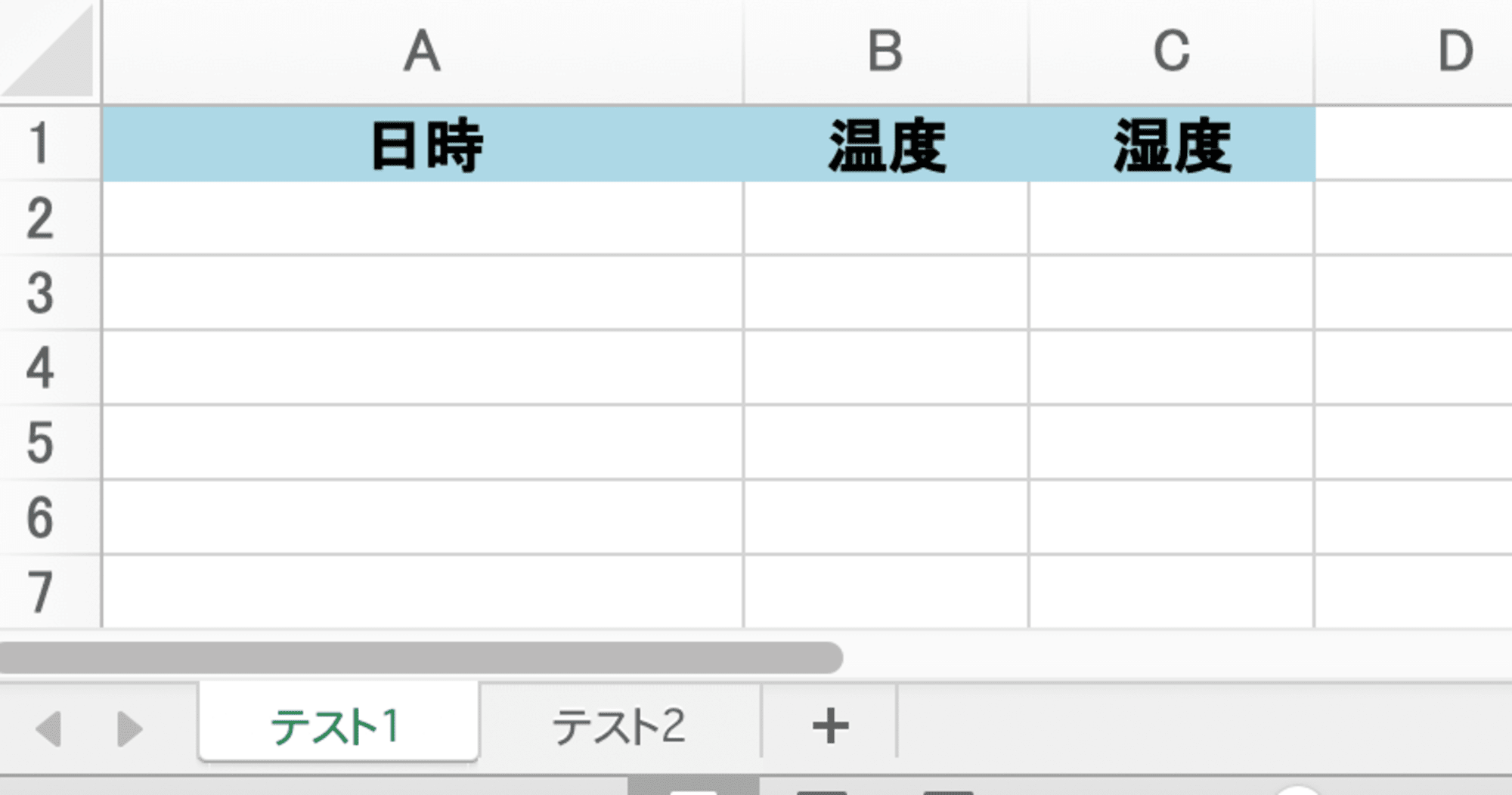
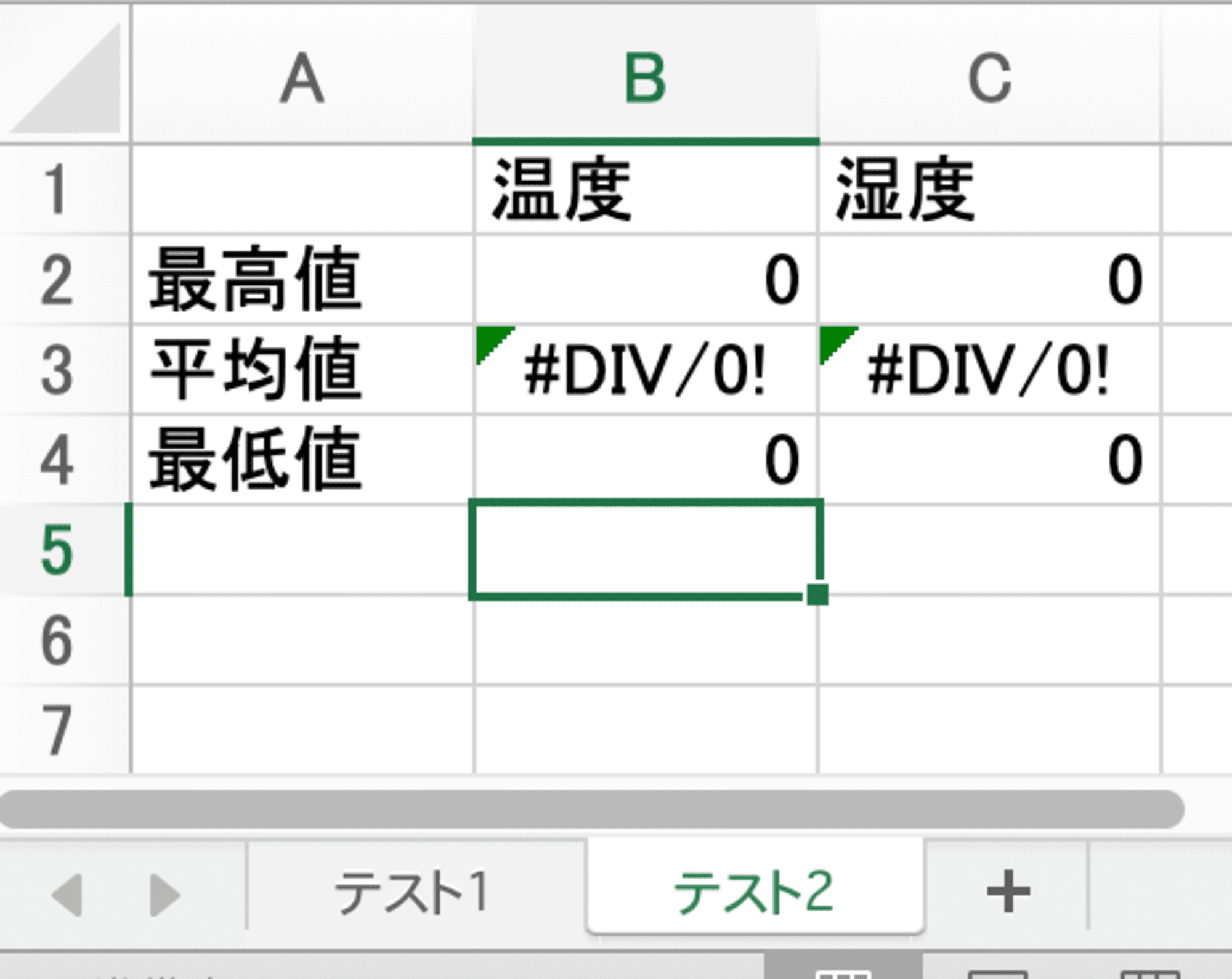
適当なExcelを用意する
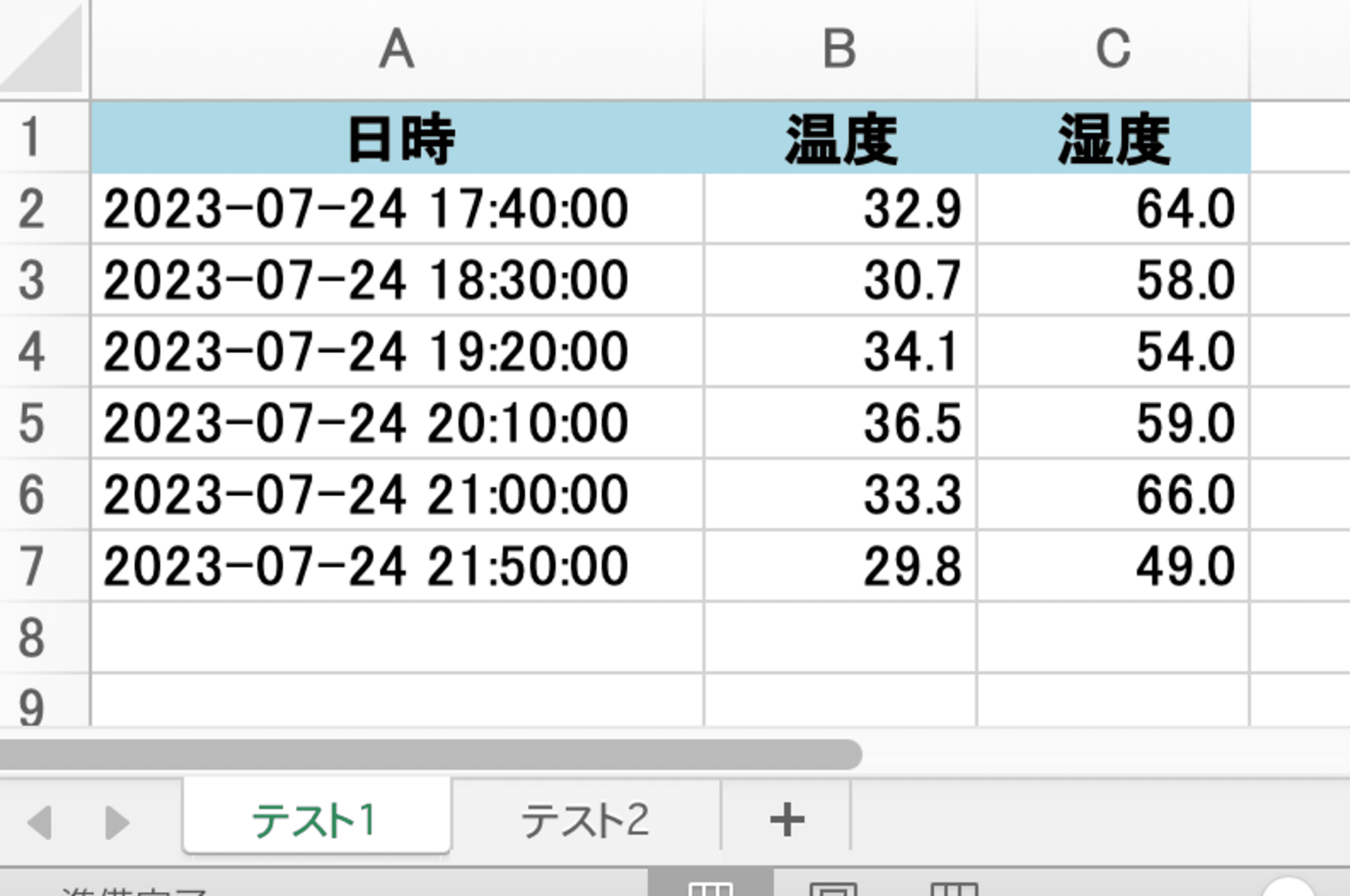
2つのシートを持つExcelを用意しました。
- テスト1
- 時系列にデータを入れる
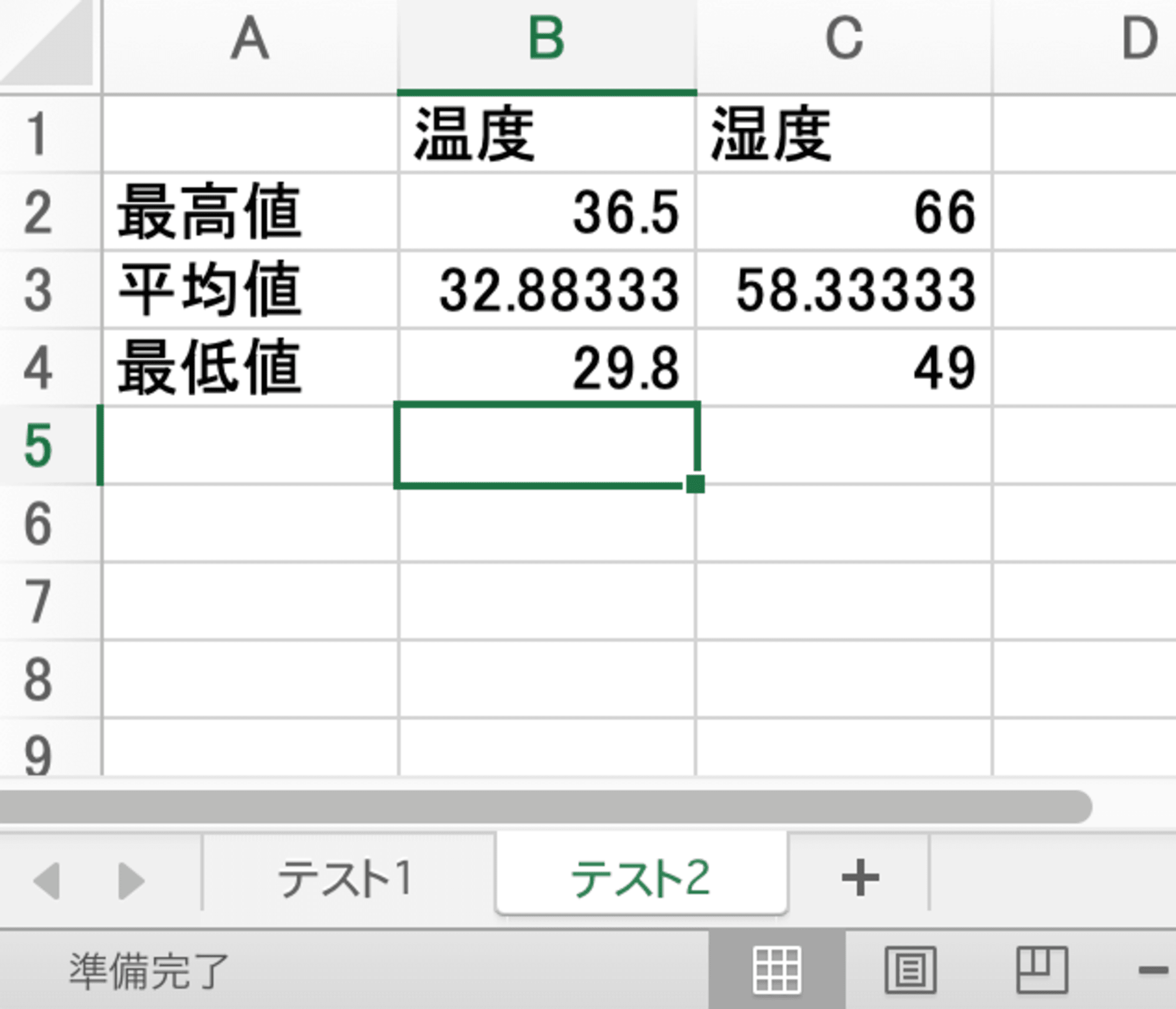
- テスト2
- 最大値などを表示する
MAX()、AVERAGE()、MIN()を使う
ExcelをS3バケットに格納する
aws s3 cp sample.xlsx s3://excel-xxx-ap-northeast-1-bucket
動作を確認する
Lambdaを実行する
今回はAPI Gateway経由で動くようにしているので、curlでgetアクセスします。
curl https://xxx.execute-api.ap-northeast-1.amazonaws.com/Prod/hello/
マネジメントコンソールで直接実行してもOKです。
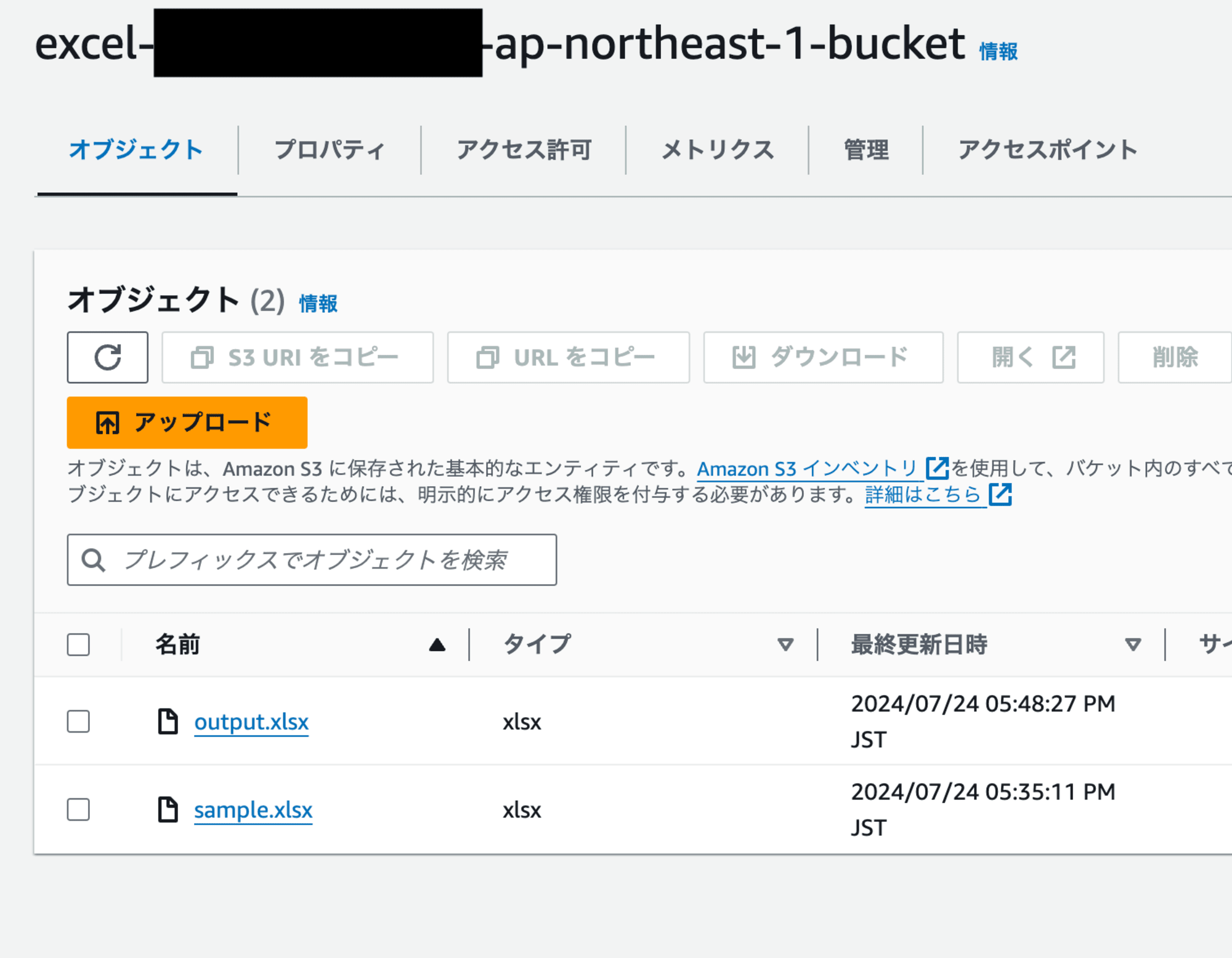
S3バケットを確認する
Excelファイルが増えていました。
Excelファイルを確認する
期待通りに更新されていました。
さいごに
LambdaでExcelを操作してみました。
テンプレートとなるExcelファイルをS3バケットに格納しておき、任意の場所にデータを追加して別ファイル化して保存する場合などで使えると思います。








